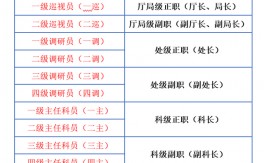
大數(shù)據(jù)處理流程
大數(shù)據(jù)處理通常包括以下幾個(gè)關(guān)鍵步驟:
1. 數(shù)據(jù)收集:
- 收集來自不同來源的數(shù)據(jù),如社交媒體、移動(dòng)設(shè)備、傳感器等。
2. 數(shù)據(jù)存儲(chǔ):
- 將收集到的數(shù)據(jù)存儲(chǔ)在適合大數(shù)據(jù)的存儲(chǔ)系統(tǒng)中,如分布式文件系統(tǒng)(HDFS)、NoSQL數(shù)據(jù)庫(kù)等。
3. 數(shù)據(jù)清洗:
- 清洗數(shù)據(jù)以去除重復(fù)、錯(cuò)誤或不完整的記錄。
4. 數(shù)據(jù)整合:
- 將來自不同來源的數(shù)據(jù)整合在一起,以便進(jìn)行分析。
5. 數(shù)據(jù)轉(zhuǎn)換:
- 將數(shù)據(jù)轉(zhuǎn)換成適合分析的格式。
6. 數(shù)據(jù)探索:
- 通過數(shù)據(jù)可視化和簡(jiǎn)單的統(tǒng)計(jì)分析來探索數(shù)據(jù),以發(fā)現(xiàn)潛在的模式和關(guān)聯(lián)。
7. 數(shù)據(jù)挖掘:
- 使用機(jī)器學(xué)習(xí)算法來發(fā)現(xiàn)數(shù)據(jù)中的模式、趨勢(shì)和關(guān)聯(lián)。
8. 數(shù)據(jù)分析:
- 進(jìn)行更深入的分析,以提取有價(jià)值的信息。
9. 結(jié)果解釋:
- 解釋分析結(jié)果,將其轉(zhuǎn)化為可操作的洞察。
10. 數(shù)據(jù)呈現(xiàn):
- 將分析結(jié)果以圖表、報(bào)告等形式呈現(xiàn)給決策者。
11. 數(shù)據(jù)應(yīng)用:
- 將分析結(jié)果應(yīng)用到實(shí)際業(yè)務(wù)中,如個(gè)性化推薦、預(yù)測(cè)分析等。
12. 數(shù)據(jù)監(jiān)控與優(yōu)化:
- 監(jiān)控?cái)?shù)據(jù)處理流程的效果,并這些步驟可能會(huì)有所重疊或迭代。大數(shù)據(jù)處理通常需要使用到一些特定的技術(shù)和工具,如Apache Hadoop、Apache Spark、NoSQL數(shù)據(jù)庫(kù)(如MongoDB、Cassandra)、數(shù)據(jù)可視化工具(如Tableau、Power BI)等。
據(jù)處理流程-圖1")
大數(shù)據(jù)處理四個(gè)步驟
大數(shù)據(jù)處理通常涉及以下四個(gè)主要步驟:
1. 數(shù)據(jù)采集:
- 收集來自不同來源的數(shù)據(jù),如社交媒體、傳感器、日志文件等。
- 需要處理的數(shù)據(jù)量可能非常龐大。
2. 數(shù)據(jù)存儲(chǔ):
- 將收集到的數(shù)據(jù)存儲(chǔ)在適合大規(guī)模數(shù)據(jù)處理的系統(tǒng)中,如分布式文件系統(tǒng)(HDFS)、NoSQL數(shù)據(jù)庫(kù)等。
- 需要考慮數(shù)據(jù)的可擴(kuò)展性、可靠性和訪問速度。
3. 數(shù)據(jù)處理:
- 對(duì)數(shù)據(jù)進(jìn)行清洗、轉(zhuǎn)換、聚合等操作,以便于分析。
- 可能需要使用如Apache Hadoop、Apache Spark等大數(shù)據(jù)處理框架來處理數(shù)據(jù)。
4. 數(shù)據(jù)分析與挖掘:
- 分析處理后的數(shù)據(jù),提取有價(jià)值的信息和洞察。
- 可以使用機(jī)器學(xué)習(xí)、統(tǒng)計(jì)分析、數(shù)據(jù)可視化等技術(shù)。
5. 數(shù)據(jù)可視化(有時(shí)也被視為一個(gè)獨(dú)立步驟):
- 將分析結(jié)果以圖形或圖表的形式展示,以便用戶更容易理解。
- 可以使用各種數(shù)據(jù)可視化工具和庫(kù)。
6. 結(jié)果應(yīng)用:
- 將分析結(jié)果應(yīng)用于實(shí)際業(yè)務(wù)場(chǎng)景,如決策支持、客戶洞察、產(chǎn)品推薦等。
每個(gè)步驟都可能包含多個(gè)子步驟和復(fù)雜的技術(shù)挑戰(zhàn),需要這些數(shù)據(jù)集的大小超出了傳統(tǒng)數(shù)據(jù)庫(kù)軟件工具的處理能力。它們通常具有以下特點(diǎn):
1. 體量大(Volume):數(shù)據(jù)量巨大,從TB到PB甚至更高級(jí)別。
2. 速度快(Velocity):數(shù)據(jù)產(chǎn)生和流轉(zhuǎn)速度快,要求處理速度和時(shí)效性高。
3. 種類多(Variety):數(shù)據(jù)類型繁多,包括結(jié)構(gòu)化、半結(jié)構(gòu)化和非結(jié)構(gòu)化數(shù)據(jù)。
4. 真實(shí)性(Veracity):數(shù)據(jù)的真實(shí)性和可靠性,包括數(shù)據(jù)的準(zhǔn)確性和完整性。
5. 價(jià)值(Value):數(shù)據(jù)中蘊(yùn)含的價(jià)值,通過分析和處理可以提供決策支持。
大數(shù)據(jù)處理系統(tǒng)的關(guān)鍵技術(shù)包括分布式計(jì)算、數(shù)據(jù)采集與處理、數(shù)據(jù)存儲(chǔ)與管理等。分布式計(jì)算通過集群的力量來處理大數(shù)據(jù),而數(shù)據(jù)采集與處理則涉及從各種來源獲取數(shù)據(jù)并進(jìn)行預(yù)處理,以便快速分析處理。數(shù)據(jù)存儲(chǔ)與管理則涉及將數(shù)據(jù)記錄在存儲(chǔ)介質(zhì)上,并進(jìn)行有效管理。
在實(shí)際應(yīng)用中,大數(shù)據(jù)處理系統(tǒng)可以應(yīng)用于金融、醫(yī)療、物聯(lián)網(wǎng)、社交媒體和城市管理等多個(gè)領(lǐng)域。例如,在金融行業(yè)中,可以通過分析交易數(shù)據(jù)來進(jìn)行風(fēng)險(xiǎn)評(píng)估和欺詐檢測(cè);在醫(yī)療領(lǐng)域,可以通過分析醫(yī)療記錄和生物傳感器數(shù)據(jù)來進(jìn)行疾病預(yù)測(cè)和治療。
目前,大數(shù)據(jù)處理系統(tǒng)的發(fā)展非常迅速,涉及到的技術(shù)包括Apache Hadoop、Apache Spark等開源框架,以及云計(jì)算、機(jī)器學(xué)習(xí)等技術(shù)。這些技術(shù)的發(fā)展進(jìn)一步推動(dòng)了大數(shù)據(jù)的處理和分析能力。
在構(gòu)建大數(shù)據(jù)處理系統(tǒng)時(shí),可以考慮使用云服務(wù)提供商的解決方案,如阿里云的大數(shù)據(jù)服務(wù),它提供了包括數(shù)據(jù)集成、開發(fā)、治理和可視化等一系列服務(wù),支持企業(yè)在數(shù)據(jù)構(gòu)建和應(yīng)用過程中降本增效,實(shí)現(xiàn)數(shù)據(jù)價(jià)值最大化。
大數(shù)據(jù)處理也與國(guó)家政策緊密相關(guān),例如中國(guó)政府在推進(jìn)全國(guó)一體化政務(wù)大數(shù)據(jù)體系建設(shè)方面也發(fā)布了相關(guān)指南,旨在加強(qiáng)數(shù)據(jù)匯聚融合、共享開放和開發(fā)利用,提高政府管理水平和服務(wù)效能。
總的來說,大數(shù)據(jù)處理系統(tǒng)是一個(gè)復(fù)雜而強(qiáng)大的工具,它能夠幫助企業(yè)和組織從海量數(shù)據(jù)中提取有價(jià)值的信息,并據(jù)此做出更明智的決策。
 微信掃一掃打賞
微信掃一掃打賞